What is GPT-4o? The Ultimate Guide to Real-Time AI

Introduction: The Dawn of the Omnimodel
We are constantly tracking the accelerating pace of artificial intelligence news and tech trends 2024, but rarely does a single announcement fundamentally redefine the trajectory of human-computer interaction. The arrival of GPT-4o, the OpenAI new model, marks one of those rare moments.
For years, users have experienced AI as a transactional entity: you type, you wait, the computer processes, and then it responds. This familiar cycle, however, fundamentally breaks down when you need an AI assistant to interact with the world around you in real time—whether that’s interpreting a live sports game, translating a spontaneous conversation, or helping you solve a complex equation shown on a screen.
This is precisely the gap the GPT-4o AI model is designed to fill.
In this ultimate guide, we will answer the critical question: what is GPT-4o? We’ll delve deep into its architecture, unpack the revolutionary GPT-4o features, compare it directly with its predecessors (GPT-4o vs GPT-4), and explore the vast GPT-4o capabilities that are ushering in the age of seamless, real-time AI. From enabling truly natural conversational AI to offering free GPT-4o access to millions, this next generation AI is poised to transform our digital lives.
Prepare to understand why the “o” in GPT-4o, which stands for “omni,” is the most significant letter in modern AI history.
Unpacking the “O”: Defining the Omnimodel Architecture
To truly grasp what is GPT-4o, we must first look past the simple version number. GPT-4o is not just a faster or slightly smarter version of GPT-4; it represents a fundamental architectural shift.
The Problem with Prior Multimodality
Previous multimodal AI systems (including earlier versions of ChatGPT) typically relied on a pipeline approach:
- Voice to Text: Audio input (your speech) was transcribed by a separate model.
- Text to Model: The text was passed to the large language model (LLM), such as GPT-4.
- Model to Text: The LLM generated a text response.
- Text to Voice: The response was converted back into audio using a separate text-to-speech model.
This chain of handoffs introduced significant latency, often resulting in delayed, robotic-sounding interactions that felt unnatural. When you spoke, the AI had to “think” for several seconds, killing the flow of conversational AI.
GPT-4o: The True Omnimodel
GPT-4o, by contrast, is an omnimodel—a single, natively multimodal AI designed from the ground up to process text, vision, and audio as one interconnected input/output stream.
This is the essence of OpenAI GPT-4o:
- Single Neural Network: It was trained across all modalities simultaneously.
- Direct Processing: It takes audio, visual, and text inputs directly and generates outputs in any combination.
- Dramatic Latency Reduction: Because there are no hand-offs between specialized models, the response time plummets.
This single-model approach allows GPT-4o to observe subtle non-verbal cues (like tone of voice or emotional inflection) and respond contextually and appropriately—a hallmark of true intelligent assistants.
Key Semantic Entities Explained
| Entity | Description | Significance to GPT-4o |
|---|---|---|
| Omnimodel | A single AI model trained end-to-end across multiple modalities (text, audio, vision). | Enables seamless, real-time integration of different inputs/outputs without translation layers. |
| Multimodal AI | AI capable of processing more than one type of data. | GPT-4o elevates this from a cobbled pipeline to a native capability. |
| Real-Time AI | AI that processes input and generates output with minimal latency (often under 300 milliseconds). | Crucial for natural conversation, live translation, and dynamic assistance. |
| Conversational AI | AI designed for natural, flowing, human-like dialogue. | GPT-4o’s speed and emotional perception revolutionize this field. |
[Related: The XAI Revolution: Demystifying AI Decisions for Trust and Transparency]
Section 3: The Breakthrough Performance: Real-Time Speed and Voice
The most immediate and striking aspect of the GPT-4o demo was the stunning performance increase, particularly in voice interaction. This is the feature that truly solidifies its claim as a real-time AI.
Human-Level Latency
In human conversation, delays longer than 250–300 milliseconds feel unnatural and interrupt the rhythm. Previous voice assistants often operated with delays well over a second or two.
GPT-4o changes this dramatically:
- Input Response Time: GPT-4o can respond to audio inputs in as little as 232 milliseconds (ms), with an average response time of 320 ms.
- Comparison: This is nearly instantaneous, comparable to the speed of a human conversational partner. For context, GPT-4 (via the slow pipeline) often took 5.4 seconds to process and respond to an audio prompt.
The Natural Language Leap
The speed isn’t just about efficiency; it unlocks entirely new interaction paradigms. The GPT-4o voice assistant doesn’t just respond quickly; it listens and processes simultaneously, allowing users to interrupt the model mid-sentence.
It also exhibits:
- Emotional Intelligence: GPT-4o can detect the user’s mood (e.g., excitement, frustration, boredom) through pitch and tone and adjust its response accordingly.
- Vocal Style Versatility: It can generate output in various emotional tones, including singing, dramatic reading, or a casual, friendly style, making the experience far richer than standard text-to-speech.
This sophisticated handling of sound, speed, and emotion is where the rubber meets the road for truly transformative conversational AI.

Section 4: Multimodal Master: Vision and Text Capabilities
While the voice capabilities of the OpenAI new model captured headlines, its proficiency across text and vision is equally critical to its status as the leading multimodal AI.
Enhanced Text Performance
Even in purely text-based tasks, GPT-4o shows marked improvement over GPT-4 Turbo:
- Benchmark Superiority: It achieves state-of-the-art results on several industry benchmarks for traditional natural language processing (NLP) tasks, often matching or slightly exceeding its predecessor while operating at twice the speed and half the cost for API users.
- Language Fluency: It boasts superior performance in non-English languages, making it a more globally accessible tool for information synthesis and creative generation.
Revolutionary AI Vision Capabilities
The true power of the “omni” architecture shines when combining sight, sound, and text. GPT-4o is exceptionally adept at processing visual data in real time.
Consider these advanced AI vision capabilities enabled by GPT-4o:
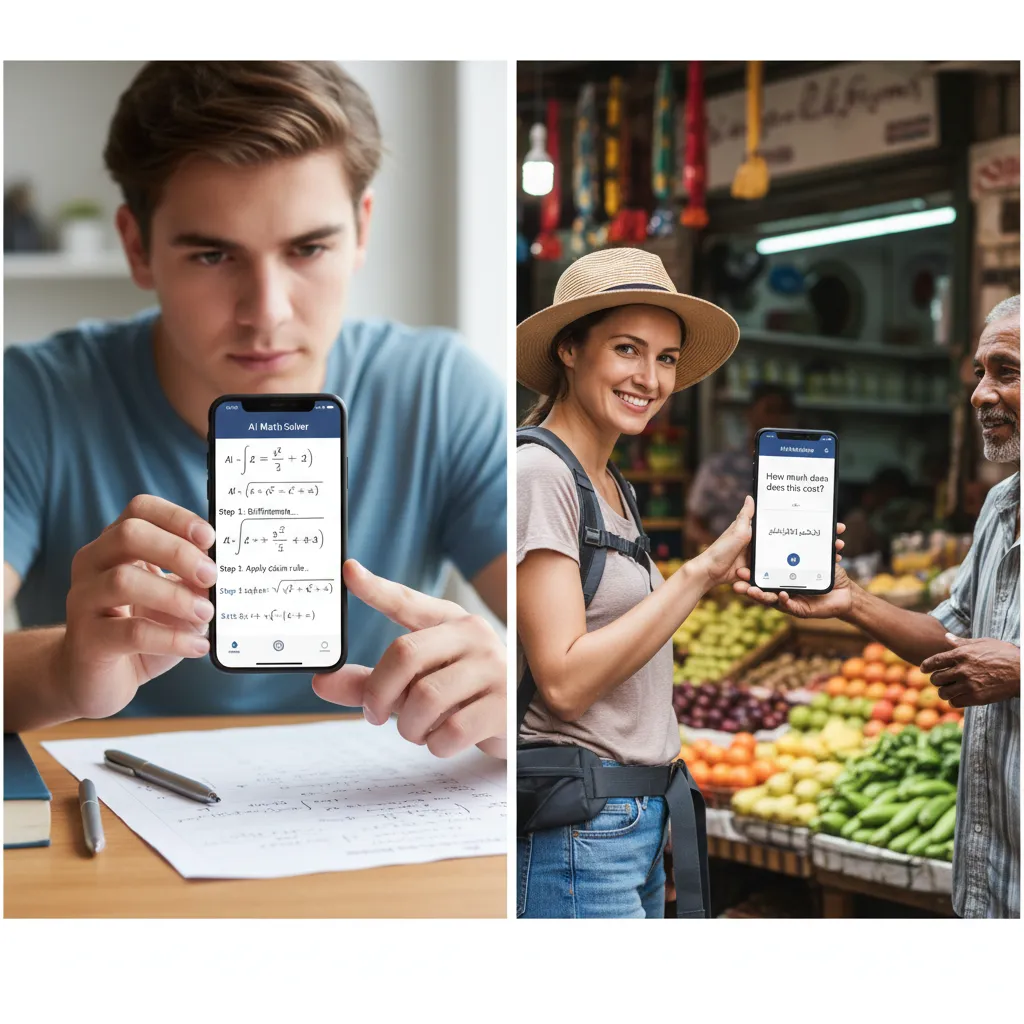
1. Real-Time Problem Solving
A user can hold up their phone camera to a complex math equation, a diagram, or a coding error. The model immediately sees the image, processes the context, and can talk the user through the solution step-by-step, using the same single AI model. It can even detect if the user’s facial expression shows confusion and proactively slow down or change its explanation style.
2. Live Environment Assistance
If you’re traveling abroad or attempting a DIY home repair, GPT-4o acts as a pocket expert. You can show it a foreign menu, and it can translate the items and verbally describe the dish’s flavor profile. You can show it a fuse box, and it can identify the components and verbally walk you through a repair process.
3. Data Visualization Interpretation
Users can upload charts, graphs, or complex visualizations. GPT-4o can not only extract the underlying data but also verbally summarize the trends, outliers, and key takeaways in an easily digestible manner.
This seamless fusion of computer vision AI and natural language is what makes the GPT-4o capabilities so revolutionary across all domains, from education to emergency support.
![]()
Section 5: The Showdown: GPT-4o vs GPT-4
For many users deciding on whether to switch or upgrade, the most pressing question is the comparative advantage. Here is a breakdown of how the next generation AI compares to its highly successful predecessor.
| Feature | GPT-4o (Omnimodel) | GPT-4 (Pipeline Multimodal) | Winner |
|---|---|---|---|
| Input Modalities | Native text, vision, and audio in one model. | Separate models for voice transcription, LLM, and text-to-speech. | GPT-4o |
| Speed (Audio Response) | Average 320 milliseconds (ms). | Average 5.4 seconds. | GPT-4o |
| Cost (API Access) | 50% cheaper than GPT-4 Turbo. | Standard pricing (higher). | GPT-4o |
| Token Limits | Generally higher context windows and capacity. | Standard high limits. | GPT-4o |
| Multilingual Support | State-of-the-art performance, superior fluency. | Excellent, but segmented. | GPT-4o |
| Real-Time Interruption | Yes, allows user interruption mid-response. | No, sequential processing required. | GPT-4o |
| Emotional Perception | Yes, natively understands tone and emotion. | Limited, primarily text-based. | GPT-4o |
The Real-World Impact of the Comparison
The difference between these models is not marginal; it’s exponential, especially concerning conversational flow. GPT-4, while brilliant, operated like a highly competent, asynchronous pen pal. GPT-4o operates like a supremely intelligent, emotionally aware, and instantaneous colleague.
This speed advantage is critical for applications like real-time translation AI. Imagine two people speaking different languages; with GPT-4o, the translation delay is negligible, allowing for a genuinely flowing conversation without the awkward pauses that plagued previous translation tools.
Section 6: Practical Applications and Real-Life Use Cases
The potential uses of GPT-4o capabilities span every sector. This AI model is not just an upgrade for researchers; it is a tool for daily life.
Education and Learning
A student struggling with a geometry problem can simply point their phone camera at the textbook diagram. Instead of typing out the entire problem, they can verbally ask, “How do I solve for X?” GPT-4o can see the diagram, understand the student’s confusion from their voice, and offer tailored, empathetic instruction, acting as a personal, infinitely patient tutor.
Travel and Accessibility
For travelers, the integration of real-time translation AI is a game-changer. Whether ordering food in Kyoto or negotiating a fare in Berlin, the device acts as a simultaneous interpreter. Furthermore, for users with visual impairments, the AI vision capabilities can describe the surrounding environment, read signs, and help navigate complex situations instantaneously.
[Related: Eco-Tourism Unpacked: Sustainable Adventures for the Conscious Traveler]
Creative and Professional Workflow
1. Coding Assistant
GPT-4o excels at coding, especially when combined with vision. A developer can photograph a whiteboard sketch of an application architecture, and GPT-4o can immediately start generating boilerplate code in Python or JavaScript, optimizing the functions, and offering verbal explanations of its logic.
2. Content Generation and Editing
The model’s ability to quickly process large amounts of visual and textual input makes it ideal for editing and content creation. It can take a raw video transcription, analyze the visual cues in the linked footage, and generate a polished, emotionally resonant script outline, all while receiving fast, verbal feedback.
[Related: Sustainable Style: Eco-Friendly Fashion Choices for the Modern Consumer]
3. Health and Wellness
As an intelligent assistant, GPT-4o can help manage complex data. While not a medical professional, it can process and summarize complicated health reports or insurance documents, explain medical terminology in plain language, and even monitor subtle changes in a user’s voice to prompt check-ins regarding stress levels or mood.
[Related: Personalized Wellness Tech: Custom Paths to Optimal Health]
Section 7: Accessing the Power: How to Use GPT-4o and Availability
One of the most appealing aspects of the OpenAI updates surrounding this launch is the broad access strategy. OpenAI aims to make the core capabilities of this advanced AI model available to everyone.
Free GPT-4o Access
A significant portion of the GPT-4o capabilities is available to all users, including those on the free tier of ChatGPT. This is a massive leap forward, democratizing high-level multimodal AI performance that was previously exclusive to paying subscribers.
Free users gain access to:
- GPT-4o Explained through standard text queries.
- Basic vision and image analysis.
- The fundamental speed and intelligence enhancements of the core model.
However, free users will have a limit on the number of GPT-4o messages they can send per day. Once the limit is reached, their session defaults back to GPT-3.5.
Paid Tiers (Plus, Team, Enterprise)
Subscribers to ChatGPT Plus, Team, and Enterprise receive significantly higher usage caps for GPT-4o and priority access to new features. This includes:
- Higher Messaging Limits: Allowing for continuous, intensive use.
- Advanced Features: Priority access to new, enhanced voice and vision tools as they roll out.
- Desktop App Access: Exclusive features within the dedicated ChatGPT desktop application, enabling faster access to the GPT-4o voice assistant through keyboard shortcuts.
API Integration
For developers, access via the OpenAI API is critical. The model name “gpt-4o” is available, offering the benefit of speed and reduced cost (50% cheaper than GPT-4 Turbo), making it highly attractive for building high-frequency, real-time AI applications. This move ensures that the wave of artificial intelligence news quickly translates into real-world applications powered by this cutting-edge model.
Section 8: Beneath the Hood: Technical Deep Dive
Understanding the technical foundation of GPT-4o explained reveals why it’s deemed the next generation AI. It’s a leap beyond standard Large Language Models (LLMs) and closer to a unified artificial general intelligence (AGI) interface.
The Training Data Paradigm
While OpenAI is proprietary about the specific training corpus, the key is the integrated training. By training the model on massive datasets where text, audio, and visual data are linked—such as captioned videos, annotated image datasets, and transcribed conversations—GPT-4o learned to find the relationships between these modalities intrinsically, not sequentially.
This intrinsic linkage means when the model sees a picture of a dog and hears the word “woof,” it connects those concepts directly within a single semantic space. This is essential for achieving the low latency required for real-time AI.
The Role of Transformer Architecture
GPT-4o still relies on the fundamental Transformer architecture, but optimized and scaled. The efficiency gains come from minimizing computational steps. In previous pipelines, multiple decoder and encoder stacks were needed for inter-model communication. GPT-4o streamlines this process, allowing for faster inference—the crucial step where the model generates its final output.
[Related: Edge AI Explained: Powering Smart Devices with Real-Time Intelligence]
Safety and Guardrails
As with all major OpenAI updates, safety is paramount. The shift to an omnimodel introduces new security challenges, particularly in synthesizing realistic voices and generating potentially harmful visual content. OpenAI has confirmed that GPT-4o undergoes extensive red-teaming and utilizes safety layers, including:
- Strict Voice Filters: Limiting the model’s ability to mimic celebrity or specific known voices to prevent impersonation fraud.
- Harmful Content Filtering: Enhanced filters across vision and text inputs to block the generation of inappropriate, illegal, or biased content.
- Model Watermarking: Efforts to trace the origin of outputs generated by the AI model.
These necessary guardrails ensure that the massive capabilities of GPT-4o are harnessed responsibly.
Section 9: The Future of AI and Human Collaboration
The introduction of GPT-4o is more than just a product launch; it’s a peek into the future of AI. The seamless, instantaneous interaction it provides shifts the paradigm from tool-user to partner-collaborator.
The Rise of the Ubiquitous AI Companion
The most profound shift is the ability of intelligent assistants to transition from reactive tools to proactive companions. Imagine an AI that is always listening (with permission), always seeing, and always ready to help instantly, much like a hyper-competent human assistant who anticipates your needs.
This level of integration paves the way for deeper applications in personal emotional support and mental wellness, moving beyond basic automation.
[Related: The Rise of AI Companions: Enhancing Daily Life and Emotional Well-being]
Tech Trends 2024: The Omnimodel Race
GPT-4o has set a new benchmark, confirming that the key tech trends 2024 will center around speed and native multimodality. Competitors are now forced to accelerate their development of similar omnimodels. The industry is moving away from modular systems (Text AI + Vision AI) towards unified, single-stack AI models that can handle everything.
This competitive environment will continue to drive down costs, increase accessibility (free GPT-4o access models will become standard), and push the boundaries of computer vision AI and conversational fluidity even further. The age of the asynchronous chatbot is ending; the era of instantaneous, context-aware digital partnership is here.

Conclusion: The Ultimate Real-Time Shift
GPT-4o is not simply an iterative upgrade; it is the realization of the promise of real-time AI. By integrating text, voice, and vision into a single, highly efficient omnimodel, OpenAI has drastically reduced latency, resulting in an experience that is finally natural, immediate, and genuinely helpful.
The fact that core GPT-4o features are being rolled out via free GPT-4o access ensures that this revolutionary technology will have an immediate and pervasive impact globally. This breakthrough moves the AI assistant from a useful but clunky tool to an intuitive, indispensable partner in our daily lives, accelerating the pace of artificial intelligence news and setting a new standard for human-computer interaction.
The future of conversational AI is here, and it is instantaneous, intelligent, and omnipresent.
FAQs: Grounded Insights on GPT-4o
Q1. What does the “o” in GPT-4o stand for?
The “o” in GPT-4o stands for “omni,” signifying that the model is omnimodal. This means it was trained as a single, unified artificial intelligence model capable of processing and generating output across all modalities—text, audio, and vision—natively and in real-time, eliminating the latency of previous multi-step AI pipelines.
Q2. Is GPT-4o available for free access?
Yes. OpenAI is providing free GPT-4o access to the general public via the free tier of ChatGPT. Free users benefit from the superior speed, intelligence, and vision capabilities of the model, though their usage will be capped, and they may be reverted to GPT-3.5 during periods of high demand.
Q3. What is the biggest performance difference between GPT-4o vs GPT-4?
The most significant performance difference is in speed and native multimodality. While GPT-4 relied on separate models for speech and vision, causing delays (often several seconds), GPT-4o responds to audio inputs in as little as 232 milliseconds. This low latency makes true real-time translation AI and natural GPT-4o voice assistant interaction possible.
Q4. Can GPT-4o interpret images and video?
Yes, the AI vision capabilities of GPT-4o are a core feature. It can interpret complex images, charts, and even live video streams (when provided via a device camera) to provide immediate context, solve problems shown visually, or describe the environment in real time. This capability integrates seamlessly with its natural language processing.
Q5. When was the GPT-4o release date?
GPT-4o was announced and demonstrated by OpenAI in May 2024, with its features immediately beginning to roll out to both free and paid users of ChatGPT and developers via the API shortly thereafter.
Q6. Is GPT-4o a single model or a system of models?
GPT-4o is a single, unified AI model. Unlike previous iterations which were “systems of models” stitched together (e.g., using one model for transcription, another for intelligence), GPT-4o is trained end-to-end to handle text, audio, and vision from input to output, making it a true omnimodel.
Q7. How does GPT-4o handle multilingual tasks like translation?
Thanks to its enhanced speed and integrated multimodal AI architecture, GPT-4o excels at real-time translation AI. It can listen to two people speaking different languages and translate back and forth instantaneously, maintaining the conversational flow and often recognizing tone and nuance better than its predecessors.
Q8. What new voice features does the GPT-4o voice assistant offer?
The GPT-4o voice assistant offers highly natural, interruptible conversation flow, comparable to human speed. Crucially, it can perceive the user’s emotion (e.g., happiness, sadness) based on their vocal tone and can also generate responses in various emotional styles (e.g., singing, joking, serious).