Claude 3.5 Sonnet vs. GPT-4o: The New AI King?

Introduction: The Generative AI Arms Race Heats Up
The year 2024 has ushered in an era of unprecedented speed in generative AI development. Just as the industry was acclimating to the lightning-fast, multimodal capabilities of OpenAI’s GPT-4o (or GPT-4 Omni), Anthropic—a major OpenAI competitor—dropped a bombshell: Claude 3.5 Sonnet. This release was not merely an incremental Claude 3 Sonnet update; it was a deliberate, powerful statement designed to challenge the reigning champion.
The stakes in this showdown between Anthropic vs OpenAI couldn’t be higher. For developers, enterprises, and everyday users, the choice between these next generation AI models determines the productivity ceiling, the creativity potential, and the ultimate cost-effectiveness of their intelligent systems. The core question dominating AI industry trends is simple: Is Claude 3.5 Sonnet the long-awaited GPT-4o killer, or does GPT-4o still hold the crown of the most capable and well-rounded large language model 2024?
This comprehensive deep dive performs a detailed AI model comparison 2024 by dissecting the capabilities, features, speed, cost, and practical applications of both models. We will go beyond mere marketing hype to examine the raw AI benchmarks and explore the groundbreaking features that define this fierce rivalry, including Anthropic’s new Claude 3.5 Artifacts feature. Whether you are a professional seeking the best AI model for coding or an analyst needing top-tier AI for data analysis, this article will provide the clarity needed for choosing an AI model in this dynamic landscape.
The New AI Titans: Introducing Claude 3.5 Sonnet and GPT-4o
To understand the comparison, we must first establish the context of each model’s design philosophy and market position.
GPT-4o: Omni-modality and Speed
When GPT-4o launched, its selling point was integration. The “o” stands for “omni,” representing its ability to natively process text, audio, and vision seamlessly through a single, highly efficient model. Prior models often required chaining together several specialized models, introducing latency. GPT-4o eliminated this, resulting in conversational speeds that felt almost instantaneous and enhanced multimodal AI models performance.
GPT-4o’s immediate impact was its accessibility and speed. It was rolled out quickly to free users, significantly democratizing access to high-tier AI capabilities and setting a challenging standard for the entire industry regarding latency and natural interaction.
Anthropic Claude 3.5 Sonnet: Precision and Performance
Anthropic, founded by former OpenAI researchers, has consistently emphasized safety, reliability, and precision. The Claude 3.5 Sonnet is positioned as the new middle tier in their stack—sitting above Haiku but offering performance that rivals and often surpasses the top-tier Claude 3 Opus. This strategic placement ensures that high-end performance is delivered at a highly competitive and cost effective AI model price point, making the Claude 3.5 Sonnet API an attractive option for high-volume enterprise use.
The primary focus of the Claude 3.5 Sonnet review centers on its marked improvements in reasoning, complex problem-solving, and, crucially, its coding proficiency. Anthropic aims to capture the market segment requiring meticulous, enterprise-grade output that minimizes hallucinations and maximizes accuracy.
Head-to-Head Benchmarks: A Data-Driven Showdown
In the AI world, benchmarks are the objective scorecards. While real-world performance can vary, standardized tests like MMLU (Massive Multitask Language Understanding) and HumanEval (coding) provide the most reliable indicators of a model’s core intelligence.
Knowledge and Reasoning: The Core IQ Test
For years, the MMLU score has served as the gold standard for assessing an AI model’s general knowledge and reasoning ability.
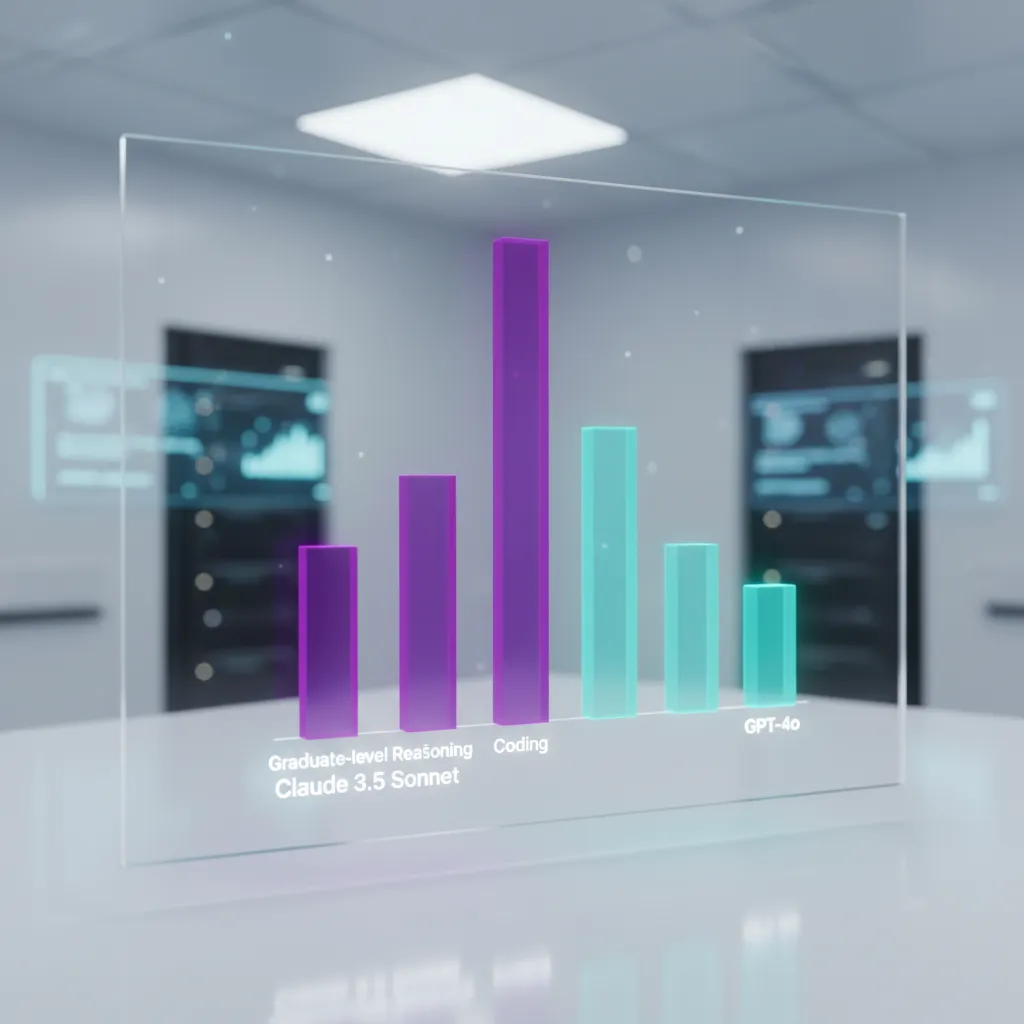
| Benchmark Category | Claude 3.5 Sonnet Score | GPT-4o Score | Analysis |
|---|---|---|---|
| MMLU (General Knowledge) | 88.7% | 88.7% | Near-identical performance, confirming both models are at the absolute frontier of general knowledge recall and complex reasoning. |
| GPQA (Graduate-Level Reasoning) | 59.4% | 56.8% | Claude 3.5 Sonnet demonstrates a slight edge in highly complex, graduate-level inference, suggesting superior ability in nuanced, high-stakes tasks. |
| MATH (Mathematical Problem Solving) | 91.0% | 87.8% | Anthropic’s model shows a clear lead in logical and mathematical reasoning. |
The data confirms that in terms of sheer cognitive power and foundational knowledge, Claude 3.5 Sonnet vs. GPT-4o is essentially a draw, with Sonnet demonstrating a minor but significant lead in structured reasoning and mathematical tasks. This positions the Anthropic Claude 3.5 as arguably the more analytically capable model for complex, internal logic problems.
[Related: master-your-money-top-personal-finance-apps-2024]
Coding and Development: Who is the Best AI Model for Coding?
For the developer community—the segment focused on AI for developers—coding benchmarks like HumanEval and GSM8K are critical. These tests measure a model’s ability to generate correct, executable code from a natural language prompt.
GPT-4 traditionally held a dominant position in coding. However, the release of Claude 3.5 Sonnet changed the narrative. Anthropic reported that Claude 3.5 Sonnet achieved scores well above GPT-4o on standard coding benchmarks, showing a marked improvement over the Claude 3 Sonnet update.
Why Claude 3.5 Excels in Coding:
- Refinement Capabilities: Claude 3.5 Sonnet shows superior ability not just to generate code, but to debug and refine existing codebases based on error feedback.
- Context Window Handling: Its ability to maintain a large context window without losing track of complex project structures is invaluable for large-scale development projects.
- Adherence to Style Guides: Many users report that Claude 3.5 is more diligent in adhering to specific coding style guides and best practices, producing cleaner, more production-ready output.
This makes the Claude 3.5 Sonnet review consensus lean heavily toward it being the best AI model for coding in 2024, particularly for Python and other popular development languages.
 A futuristic bar chart comparing the performance benchmarks of Claude 3.5 Sonnet and GPT-4o in various reasoning and knowledge tasks.
A futuristic bar chart comparing the performance benchmarks of Claude 3.5 Sonnet and GPT-4o in various reasoning and knowledge tasks.
Vision and Multimodal Capabilities
Both models are classified as multimodal AI models, meaning they can interpret and generate content across different data types, including images.
Claude 3.5 Vision Capabilities
Anthropic states that Claude 3.5 Sonnet has dramatically improved its Claude 3.5 vision capabilities, often surpassing GPT-4o’s performance in visual reasoning tests. Key strengths include:
- Chart Interpretation: Claude 3.5 is exceptionally proficient at extracting data and interpreting complex visualizations, such as reading detailed bar graphs, pie charts, and even nuanced financial reports presented as images. This is a game-changer for AI for data analysis.
- Text Extraction: Superior ability to extract text from challenging, distorted, or low-resolution images.
- Spatial Reasoning: Better understanding of spatial relationships and object interaction within an image.
GPT-4o’s Vision Strength
GPT-4o’s vision strength lies not in raw benchmark superiority, but in its speed and integration. The immediate, low-latency processing of image and video input makes it ideal for real-time applications, such as a mobile app that instantly translates text from a street sign or identifies a complex object immediately upon capturing the image.
The verdict here depends on intent: for deep, accurate, and analytical visual understanding, Claude 3.5 Sonnet is arguably ahead. For rapid, interactive, real-time visual processing, GPT-4o’s lower latency shines.
 An AI model accurately interpreting a complex chart and providing a detailed analysis of the visual data.
An AI model accurately interpreting a complex chart and providing a detailed analysis of the visual data.
Feature Deep Dive: Artifacts vs. Omni-modality
Beyond benchmarks, the user experience is defined by unique features. This is where Anthropic and OpenAI truly diverge, offering two different approaches to intelligent agent AI interaction.
Claude 3.5’s Game-Changer: The Artifacts Feature
Perhaps the most talked-about development in the Claude 3.5 Sonnet review is the introduction of Claude 3.5 Artifacts feature. This capability transforms the typical chat interface into a dynamic, interactive workspace.
What are Artifacts?
Artifacts are the immediate, visible output of Claude’s creative or functional processes, rendered in a separate, dedicated window alongside the chat interface.
- Coding Artifacts: If you ask Claude to write a website component, the resulting HTML, CSS, and JavaScript are instantly rendered as a live, interactive webpage in the Artifacts window. You can see the code and the result simultaneously.
- Design Artifacts: If Claude generates a diagram, a marketing image, or a simple UI sketch, it appears in the Artifacts window, allowing for immediate visualization and iterative refinement within the same session.
- Data Artifacts: When analyzing data, Claude can render interactive tables, charts, or SQL query results directly in the workspace.
This shifts the interaction from purely conversational to collaborative. Instead of copying and pasting code or data into a separate editor, the user works directly with the output. This capability is a significant boon for AI for developers and anyone engaging in iterative creative or analytical work. If this feature is expanded to the intelligent agent AI level, where users can deploy these Artifacts directly, it could fundamentally redefine productivity tools.
[Related: mastering-generative-ai-art-tools-trends-creative-futures/]
GPT-4o’s Omnipresence: Speed and Seamless Integration
GPT-4o’s primary feature advantage remains its deep integration across modalities and its unprecedented speed. It’s an omnichannel experience, delivering a unified performance across vision, text, and audio.
- Low Latency: GPT-4o boasts dramatically lower response latency, making real-time human-AI conversation natural and efficient.
- Tool Integration: OpenAI’s vast ecosystem of plugins and custom GPTs means GPT-4o integrates seamlessly into existing workflows and enterprise solutions, often acting as the backbone for hundreds of specialized agents.
- Accessibility: Its availability across free tiers and rapid integration into the main ChatGPT interface means millions of users have immediate access to its top-tier intelligence, cementing its position as a market leader.
While Artifacts offer a superior single-session workflow, GPT-4o offers superior ecosystem integration and lower latency for rapid, transactional interactions. The choice often comes down to depth (Claude) versus breadth and speed (GPT-4o).
 Illustration of the Claude 3.5 Sonnet ‘Artifacts’ feature showing a user interacting with a live code preview next to the chat interface, emphasizing the real-time, interactive workflow.
Illustration of the Claude 3.5 Sonnet ‘Artifacts’ feature showing a user interacting with a live code preview next to the chat interface, emphasizing the real-time, interactive workflow.
The Practical Metrics: Speed, Cost, and Accessibility
For businesses and power users, the performance metrics that truly matter are those affecting the bottom line: speed and price. This comparison focuses on the Claude 3.5 Sonnet pricing and AI speed comparison relative to GPT-4o.
API Pricing Comparison: Dollar-for-Dollar Value
Both models are positioned in the “premium” tier, but the definition of “cost effective AI model” is constantly shifting. The pricing models below reflect the typical input and output token costs as of the latest updates, focusing on commercial API usage.
| Model | Input Price (per 1M tokens) | Output Price (per 1M tokens) | Context Window |
|---|---|---|---|
| Claude 3.5 Sonnet | ~$3.00 | ~$15.00 | 200K tokens |
| GPT-4o | ~$5.00 | ~$15.00 | 128K tokens |
The table reveals a critical differentiator: the Claude 3.5 Sonnet API is significantly cheaper on input tokens (the cost of sending data to the model). For applications that require analyzing massive documents, processing large datasets, or handling complex RAG (Retrieval-Augmented Generation) architectures, this pricing structure makes Claude 3.5 Sonnet a much more cost effective AI model.
Furthermore, Claude 3.5 Sonnet offers a substantially larger 200K context window by default, compared to GPT-4o’s 128K. This difference is vital for tasks requiring deep, sustained memory, such as summarizing entire technical manuals, analyzing multi-file code repositories, or maintaining a long, intricate chat history.
Latency and Throughput: Which is Faster for Production?
Speed is often the most subjective metric, as it relies on server load and specific application demands. However, generalized performance tests show a clear pattern in the AI speed comparison:
- GPT-4o (Omni): Designed for extreme low latency. Its unified architecture allows it to deliver the first token exceptionally fast, making it feel instantaneous, especially in chat and audio/vision applications. This is its core strength.
- Claude 3.5 Sonnet: While not as blisteringly fast in first token delivery as GPT-4o, Claude 3.5 Sonnet offers higher throughput—meaning it can process and complete longer, more complex tasks quicker overall. Its superior performance on heavy reasoning tasks minimizes the need for follow-up prompts, effectively saving time on the entire workflow.
For real-time, user-facing applications like chatbots, GPT-4o is the established choice. For back-end processing, batch jobs, and enterprise workflows demanding comprehensive accuracy over sheer speed, Claude 3.5 Sonnet’s efficiency and lower input cost give it a decisive edge.
 An infographic comparing the cost and speed metrics of Claude 3.5 Sonnet against other leading AI models, highlighting the input token cost advantage of Claude 3.5 for high-volume input tasks.
An infographic comparing the cost and speed metrics of Claude 3.5 Sonnet against other leading AI models, highlighting the input token cost advantage of Claude 3.5 for high-volume input tasks.
Use Case Analysis: Choosing the Right Tool for the Job
The true test of any large language model 2024 is how it performs in real-world scenarios. The decision of choosing an AI model often hinges on specific departmental needs.
For Creative Professionals and Content Generation
When it comes to generating high-quality, long-form content, the nuances of tone and creativity matter significantly.
- Claude 3.5 Sonnet: Historically, Anthropic models have been praised for their sophisticated, natural, and human-sounding text generation, often displaying superior coherence in longer narratives. For complex technical writing, novel concept generation, and creative tasks requiring emotional nuance, Claude 3.5 often delivers more polished, ready-to-publish drafts.
- GPT-4o: Excellent for speed-driven content creation, such as drafting email replies, generating social media snippets, or rapidly outlining articles. Its versatility across modalities (e.g., generating text and an image concept simultaneously) can streamline certain creative workflows.
Verdict: For highly polished, authoritative content, Claude 3.5 Sonnet. For high-volume, quick iterations, GPT-4o.
[Related: unlock-potential-top-ai-tools-everyday-productivity/]
For Data Analysts and Researchers
The ability to ingest, interpret, and manipulate data is paramount for roles involving AI for data analysis.
- Claude 3.5 Sonnet: The combination of superior mathematical benchmarks, exceptional Claude 3.5 vision capabilities for chart interpretation, and the large context window makes it the preferred tool for deep analytical work. A data analyst can feed Claude 3.5 massive technical documents or complex raw data, rely on its high accuracy, and utilize the Artifacts feature to visualize the analysis interactively.
- GPT-4o: Excels when data analysis is part of a broader, multimodal task, such as analyzing a financial spreadsheet image and then immediately voicing a summary of the findings. Its strength is in the rapid synthesis of information from disparate, mixed inputs.
Verdict: Claude 3.5 Sonnet provides deeper, more reliable analytical output; GPT-4o provides faster, more versatile multimodal analysis.
For Enterprise and High-Volume Workloads
Enterprises prioritize reliability, consistency, and cost-efficiency at scale.
- Cost Effective AI Model: As established, the significantly lower input token cost of Claude 3.5 Sonnet makes it much more economical for enterprise RAG and internal data processing, potentially saving thousands monthly on high-volume use cases.
- Reliability and Safety: Anthropic’s commitment to safety translates into highly reliable models less prone to catastrophic failures or sensitive information leaks—a major factor in large-scale enterprise adoption.
- Scalability: Both models offer robust API access. However, the higher ceiling of the Claude 3.5 context window (200K tokens) means it can handle larger batch processes without needing to break down inputs, simplifying large-scale deployment.
Verdict: For core enterprise data processing, cost-efficiency favors Claude 3.5 Sonnet. For front-end customer interaction requiring immediate responsiveness, GPT-4o often wins due to low latency.
The Larger Narrative: Anthropic vs OpenAI
The rivalry between Anthropic and OpenAI is more than just a specification race; it defines the future direction of the tech trends 2024.
OpenAI, with its massive backing and widespread platform integration, aims for general artificial general intelligence (AGI) through rapid iteration and democratization. GPT-4o symbolizes this approach: powerful, ubiquitous, and immediately accessible. Its role is to define the standard user experience.
Anthropic, in contrast, focuses on constitutional AI and safety, viewing performance through the lens of robustness and accuracy. The release of Anthropic Claude 3.5 as a clear benchmark leader in several key cognitive areas signals that high-quality performance does not have to be sacrificed for safety.
The rise of Claude 3.5 Sonnet confirms that the competitive pressure is delivering massive benefits to consumers. This tight competition—the GPT-4o killer vs. the incumbent champion—forces both companies to innovate at a breakneck pace, accelerating the development of truly intelligent agent AI.
[Related: the-depin-revolution-building-tomorrows-decentralized-physical-infrastructure/]
Conclusion: Declaring the New AI King?
The question of whether Claude 3.5 Sonnet is the new AI king is nuanced, but one thing is clear: it has delivered a critical blow to GPT-4o’s brief reign of unchallenged superiority.
The Verdict in a Nutshell:
- If Accuracy and Depth Matter Most: Claude 3.5 Sonnet takes the crown. Its superior performance in coding, mathematical reasoning, graduate-level knowledge, and complex visual analysis (especially charts) makes it the most intellectually powerful and precise model available at its tier.
- If Speed and Ecosystem Integration Matter Most: GPT-4o remains the champion. Its unparalleled low latency, seamless integration across audio/vision/text, and widespread platform adoption make it the most versatile and responsive model for real-time and consumer-facing applications.
However, the introduction of the Claude 3.5 Artifacts feature provides a significant workflow advantage that GPT-4o currently lacks, particularly for developers and analysts. When factoring in the lower Claude 3.5 Sonnet pricing for input tokens and its larger context window, Anthropic has provided compelling economic and performance reasons for enterprises to switch.
In the rapidly evolving world of generative AI news, the new AI King is not a single model, but a pair of highly specialized titans. For technical professionals seeking the absolute best in reliability and complex processing, Claude 3.5 vs GPT-4 Omni tilts decisively toward Claude 3.5 Sonnet. For the rest of the world, GPT-4o remains the speedy, accessible, jack-of-all-trades.
The true winner, however, is the user, who now has access to two phenomenal next generation AI models pushing the boundaries of what’s possible. It’s an exciting time to be building with AI, and choosing an AI model has never offered such high-performance options.
Frequently Asked Questions (FAQs)
Q1. What is Claude 3.5 Sonnet?
Claude 3.5 Sonnet is Anthropic’s new state-of-the-art middle-tier large language model released in 2024, offering performance that rivals and often surpasses its competitors’ flagship models, including GPT-4o, particularly in reasoning, coding, and vision. It is part of the latest update in the Anthropic Claude 3 family.
Q2. How does Claude 3.5 Sonnet compare to GPT-4o in coding ability?
Based on standardized tests like HumanEval, Claude 3.5 Sonnet has established itself as potentially the best AI model for coding in 2024. Developers praise its ability to produce cleaner, more accurate, and more complex code solutions, often outperforming GPT-4o in debugging and multi-file project handling.
Q3. What is the Claude 3.5 Artifacts feature and why is it important?
The Claude 3.5 Artifacts feature is a new interactive workspace that renders the model’s outputs (like code, diagrams, or documents) in a live, adjacent window next to the chat interface. This significantly improves iterative workflows for AI for developers and designers by allowing immediate visualization and refinement of the model’s generated output.
Q4. Is Claude 3.5 Sonnet a cost effective AI model compared to GPT-4o?
Yes. While the output costs are similar, the Claude 3.5 Sonnet pricing for input tokens (data sent to the model) is generally lower than GPT-4o’s. Additionally, its larger context window (200K vs. 128K tokens) means it can handle larger, more complex tasks in a single query, leading to higher overall cost efficiency for high-volume enterprise users utilizing the Claude 3.5 Sonnet API.
Q5. Which model is better for real-time interaction and speed?
GPT-4o is currently superior for applications requiring extreme low latency and real-time interaction, such as voice assistants and immediate, rapid visual interpretation. Its unified “omni-modal” architecture enables quicker first-token response times in the AI speed comparison.
Q6. Does Claude 3.5 have good vision capabilities?
Yes, the Claude 3.5 vision capabilities are highly advanced. Anthropic reported that the model excels specifically in complex visual tasks like interpreting charts, graphs, and technical diagrams for AI for data analysis, often achieving higher accuracy than GPT-4o in detailed visual reasoning.
Q7. Is Claude 3.5 Sonnet considered a “GPT-4o killer”?
While Claude 3.5 Sonnet is a powerful GPT-4o killer contender—matching or exceeding GPT-4o in key benchmarks like coding and reasoning—it is more accurate to view it as the primary challenger. It successfully shattered GPT-4o’s brief monopoly on top performance, forcing a genuine competition between these next generation AI models.
Q8. What is the main difference between Claude 3.5 Sonnet and the previous Claude 3 Sonnet update?
Claude 3.5 Sonnet represents a massive leap in core intelligence and functionality over the previous Claude 3 Sonnet. The main differences are superior scores across major AI benchmarks, vastly improved coding and vision abilities, and the introduction of the transformative, interactive Claude 3.5 Artifacts feature.